GPT-5.5: Čo prináša nový model OpenAI a ako mení AI vyhľadávanie
OpenAI 23. apríla 2026 vydalo GPT-5.5 (interný kódový názov „Spud") — prvý plne pretrénovaný base model od GPT-4.5, natívne omnimodálny, s 1M tokens context window a state-of-the-art na 14 verejných benchmarkoch. Pozrite si kľúčové novinky, benchmark čísla, API ceny ($5/$30 za 1M tokenov input/output, Pro $30/$180), porovnanie s Claude Opus 4.7 a Gemini 3.1 Pro — a hlavne, čo to znamená pre weby, ktoré chcú byť citované v ChatGPT Search a ďalších AI engine-och.

Posledná aktualizácia: 25. apríla 2026 · Autor: Ing. Lukáš Szudár · Primárny zdroj: OpenAI — Introducing GPT-5.5
TL;DR: OpenAI 23. apríla 2026 oficiálne vydalo GPT-5.5 (interný kódový názov „Spud") — prvý plne pretrénovaný base model od GPT-4.5. Je natívne omnimodálny (text + obraz + audio + video), má 1M tokens context window v API a dosahuje state-of-the-art na 14 verejných benchmarkoch (vs 4 pre Claude Opus 4.7 a 2 pre Gemini 3.1 Pro). API cena je 2× vyššia než GPT-5.4 — $5/$30 za 1M tokenov input/output, Pro variant $30/$180. Pre tých, čo chcú byť citovaní v AI vyhľadávačoch, prináša GPT-5.5 hlbšie agentic capabilities a väčší dôraz na štruktúrovaný, citovateľný obsah.
Čo je GPT-5.5 a kedy bol vydaný
Kľúčové zistenie: GPT-5.5 je nová generácia OpenAI modelu vydaná 23. apríla 2026. Interný kódový názov „Spud" naznačuje, že ide o prvý plne pretrénovaný base model od GPT-4.5 (2025) — nie o ďalšiu inkrementálnu fine-tuning vrstvu. Dostupný je v ChatGPT Plus, Pro, Business a Enterprise, a v API od 24. apríla 2026.
OpenAI ho označuje za „nový druh inteligencie" a podľa The New Stack ide o najsilnejší pokrok v sérii GPT-5 odkedy bola spustená. Hlavná tézaa OpenAI: model nielen odpovedá na otázky — plánuje, používa nástroje, kontroluje vlastnú prácu a iteruje, kým úloha nie je hotová. Tento posun smerom k agentic capabilities sa odzrkadľuje vo všetkých kľúčových benchmarkoch.
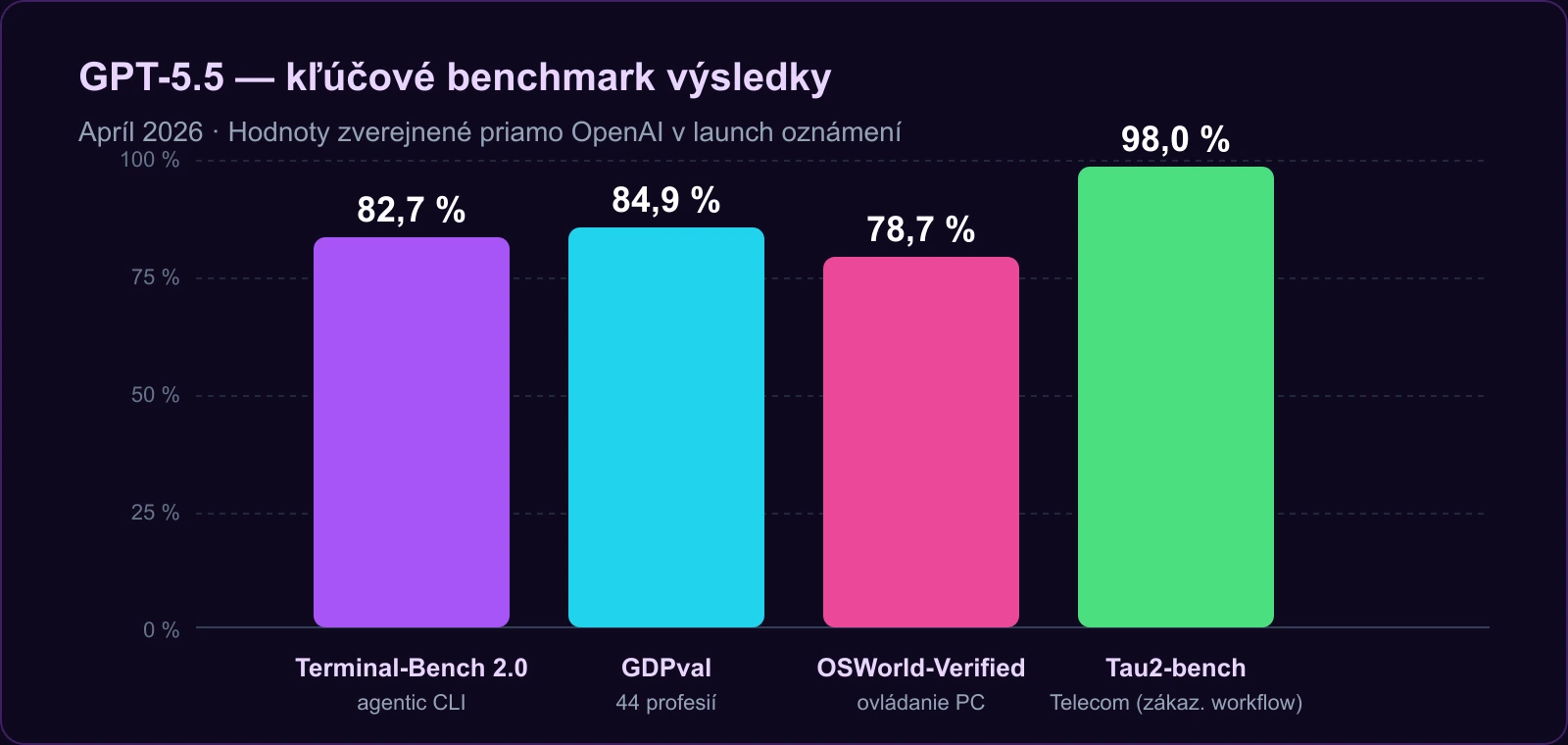
Tri kľúčové novinky GPT-5.5
Kľúčové zistenie: GPT-5.5 prináša tri kvalitatívne posuny — natívnu omnimodalitu (jeden model spracuje text aj obraz, audio a video bez prepínania), state-of-the-art agentic coding (Terminal-Bench 2.0 na 82.7 %) a 2× lepší long-context retrieval (MRCR v2 pri 1M tokenoch skočil z 36,6 % na 74,0 %).
1. Natívna omnimodalita (text + obraz + audio + video)
Podľa Axios ide o prvý plne pretrénovaný base model od GPT-4.5. Predošlé verzie pridávali multimodalitu cez adaptéry. GPT-5.5 je natívne omnimodálny — text, obrázky, audio a video spracúva v rámci jednej architektúry. To znamená nižšiu latenciu, vyššiu konzistentnosť odpovedí naprieč modalitami a najmä lepšie pochopenie kontextu, keď sa modality kombinujú.
2. Agentic coding na úrovni state-of-the-art
Najsilnejší benchmark pre vývojárov je Terminal-Bench 2.0 — meria, či model dokáže autonómne plánovať, iterovať a koordinovať nástroje v command-line workflow. GPT-5.5 dosahuje 82,7 % oproti 69,4 % pri Claude Opus 4.7. Ďalšie kľúčové čísla podľa OpenAI:
- GDPval (44 profesií, knowledge work): 84,9 %
- OSWorld-Verified (ovládanie reálneho počítača): 78,7 %
- Tau2-bench Telecom (zákaznícke workflows): 98,0 % bez prompt tuningu
- FrontierMath Tier 4: 35,4 % (vs 22,9 % pri Claude Opus 4.7)
3. Long-context skok cez 1M tokenov
API má 1M tokens context window, Codex 400K. Najpôsobivejšia metrika je MRCR v2 (Multi-Round Co-reference Resolution) pri 1M tokenoch: GPT-5.5 dosahuje 74,0 % oproti 36,6 % pri GPT-5.4 — viac ako dvojnásobok. To znamená, že model po prvý raz reálne dokáže pracovať s celou dokumentáciou alebo veľkým kódom v jednom prompte bez „zabúdania" detailov z prvej polovice.

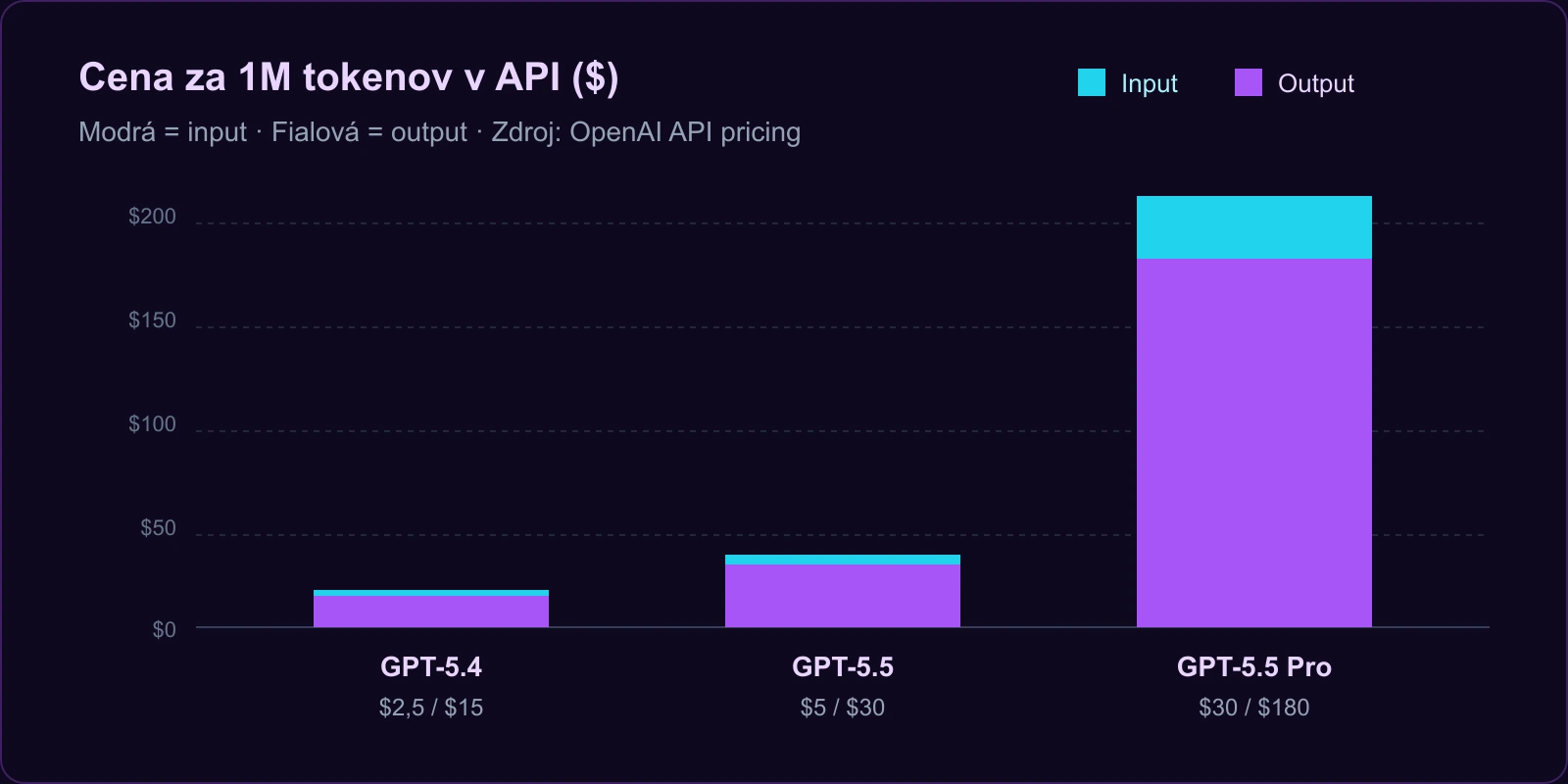
Cena: 2× vyššia než GPT-5.4
Kľúčové zistenie: GPT-5.5 stojí v API $5 za 1M input tokenov a $30 za 1M output tokenov. Vyšší variant GPT-5.5 Pro stojí $30 / $180. To je podľa The Decoder presne 2× cena GPT-5.4. OpenAI však argumentuje, že vyššia token-efficiency znižuje reálne náklady na úlohu.
Doplnkové ceny:
- Batch a Flex: 50 % štandardnej API ceny (vhodné pre asynchrónne workloady)
- Priority processing: 250 % (2,5× cena, garantovaná latencia)
- Per-token latencia: rovnaká ako GPT-5.4 v reálnej prevádzke
Sam Altman v launch oznámení zdôraznil, že model síce má vyššiu cenu za token, ale spotrebuje menej tokenov na rovnaký výsledok — takže reálny rozdiel pre väčšinu úloh nie je 2×, ale výrazne menší.
GPT-5.5 vs Claude Opus 4.7 vs Gemini 3.1 Pro
Kľúčové zistenie: Žiaden z troch frontier modelov nedominuje vo všetkom. GPT-5.5 vyhráva v agentic a knowledge-work workflows (Terminal-Bench, GDPval, OSWorld), Claude Opus 4.7 v čistom GitHub coding (SWE-bench Pro a Verified) a Gemini 3.1 Pro v cost-efficiency a context length. Voľba modelu by mala kopírovať reálny use case, nie marketing.
| Benchmark / parameter | GPT-5.5 | Claude Opus 4.7 | Gemini 3.1 Pro |
|---|---|---|---|
| Terminal-Bench 2.0 (agentic CLI) | 82,7 % | 69,4 % | 68,5 % |
| SWE-bench Verified | ~85 % | 87,6 % | 80,6 % |
| SWE-bench Pro | 58,6 % | 64,3 % | 54,2 % |
| FrontierMath Tier 4 | 35,4 % | 22,9 % | — |
| MRCR v2 @ 1M tokens | 74,0 % | 32,2 % | — |
| Cena (input / output per 1M) | $5 / $30 | $15 / $75 | $1,25 / $10 |
| Context window | 1M | 500K | 2M |
| Natívne omnimodálny | Áno | Čiastočne | Áno |
Pomlčka („—") znamená, že prevádzkovateľ daného modelu k benchmarku verejne neudal výsledok. Hodnoty pre Gemini 3.1 Pro pochádzajú z Google DeepMind model card. Claude Opus 4.7 zaznamenal výrazný pokles na MRCR v2 (z 78,3 % pri Opus 4.6 na 32,2 %); Anthropic argumentuje, že MRCR nereflektuje reálne použitie a odporúča alternatívny benchmark GraphWalks.
Pre vývojárske tímy, ktoré pracujú primárne s GitHub issues a pull-request automatizáciou, ostáva Claude Opus 4.7 silnejšou voľbou. Pre agentic workflows v termináli, knowledge-work úlohy a long-context analýzy je GPT-5.5 jasný favorit. Gemini 3.1 Pro je rozumný kompromis pre projekty s veľmi dlhým kontextom (2M tokens) a tlakom na cenu — pri ~4× nižších API tarifoch než GPT-5.5.
Čo GPT-5.5 znamená pre AI optimalizáciu webu
Kľúčové zistenie: GPT-5.5 zvyšuje nároky na štruktúrovanosť obsahu. Lepšie agentic capabilities znamenajú, že OAI-SearchBot a ChatGPT-User fetchujú hlbšie kontexty — model si vie pozrieť celú dokumentáciu, nie iba snippet. Natívna omnimodalita zase znamená, že obrázky a video sa stávajú citačným zdrojom — alt texty a Schema.org markup pre obrázky už nie sú „nice to have".
Tri praktické posuny pre weby, ktoré chcú byť v ChatGPT Search citované:
- Agentic fetch > statický snippet: 1M context znamená, že AI engine môže prečítať celú dokumentáciu jednou návštevou. Štandard llms.txt nadobúda na význame — nasmerujte AI bota priamo na štruktúrovanú verziu obsahu.
- Omnimodálny obsah: diagramy, schémy a infografiky sú teraz priamo „čítané" modelom. Pridajte popisy v alt atribútoch a
ImageObjectschema. Detailne v článku Technical GEO: robots.txt, Schema Markup a prístup AI botov. - Hlbšia citácia > jednorazové spomenutie: agentic model odcituje zdroj, ktorý odpovedá na celú reťazca otázok, nie len na prvú. Štruktúrujte obsah do reťazca H2 + citability blokov, ako popisujeme v GEO optimalizačnom návode.
Kto má základ urobený podľa odporúčaní v pillar článku o AI optimalizácii webu a v audite AI crawlerov, nestratí ani sekundu — GPT-5.5 zvýhodňuje presne ten obsah, ktorý už dnes funguje pre ChatGPT Search.
Často kladené otázky
Kedy bol GPT-5.5 vydaný a kde je dostupný?
OpenAI oficiálne vydalo GPT-5.5 23. apríla 2026. V ChatGPT je dostupný pre Plus, Pro, Business a Enterprise používateľov. V Responses a Chat Completions API je dostupný od 24. apríla 2026 pod identifikátorom gpt-5.5 (a gpt-5.5-pro pre vyšší variant).
Aký je rozdiel medzi GPT-5.5 a GPT-5.5 Pro?
GPT-5.5 Pro je výkonnejší variant s rovnakou architektúrou, ale s vyšším výpočtovým rozpočtom na úlohu. Cena je 6× vyššia ($30/$180 vs $5/$30 za 1M tokenov). Pro variant je cielený na výskum, komplexnú matematiku a multistep agentic workflows. Pre väčšinu použití stačí štandardná verzia.
Je GPT-5.5 lacnejší ako GPT-5.4?
Nie — cena za token je presne 2× vyššia ($5/$30 vs $2,50/$15). OpenAI však tvrdí, že vyššia token-efficiency znamená menej tokenov na rovnakú úlohu, takže reálny rozdiel je menší. Pre asynchrónne workloady cez Batch alebo Flex API platíte len 50 % ceny.
Je GPT-5.5 lepší než Claude Opus 4.7?
Záleží na use case. GPT-5.5 vyhráva na agentic benchmarkoch (Terminal-Bench 82,7 % vs 69,4 %), GDPval, OSWorld a FrontierMath. Claude Opus 4.7 ostáva silnejší v čistom GitHub coding (SWE-bench Pro 64,3 % vs 58,6 %) a tool-call reliability (MCP-Atlas 79,1 % vs 75,3 %). Pre vývoj cez terminál a knowledge work je lepší GPT-5.5.
Čo znamená „Spud" a „omnimodal"?
„Spud" je interný kódový názov modelu, použitý pri tréningu — verejnosť ho zachytila cez Axios. „Omnimodal" znamená, že model spracúva text, obraz, audio a video v rámci jednej architektúry — nie cez samostatné adaptéry. Je to kvalitatívny posun voči multimodalite, ktorá kombinovala oddelené komponenty.
Ako zvýšim šancu, že ChatGPT s GPT-5.5 cituje môj web?
Tri základné kroky: (1) povoľte v robots.txt OAI-SearchBot aj ChatGPT-User; (2) štruktúrujte obsah do citability blokov, teda 40-60 slov samostatných odpovedí pod každým H2; (3) pridajte llms.txt a kompletný Schema.org markup. Sledovanie reálnych citácií v čase robí napríklad platforma Optimalizácia pre AI.
O autorovi: Ing. Lukáš Szudár je zakladateľ platformy Optimalizácia pre AI (optimalizaciapreai.sk) — SaaS nástroj na sledovanie citácií v AI vyhľadávačoch (Perplexity, ChatGPT Search, Google AI Overviews, Gemini, Claude). Od roku 2026 buduje slovenský produkt na sledovanie AI viditeľnosti — aktuálne meriame citácie pre desiatky domén. Odporúčania v tomto článku vychádzajú zo sledovania reálnych zmien v citačných patternoch po launchi nových AI modelov.
Zdroje
Odporúčame prečítať
Sledujte, ako AI vyhľadávače citujú váš web
Vyskúšajte Optimalizáciu pre AI zadarmo